- | Home |
- Company |
- Contact |
- News |
- S/ware Eng |
- Standards |
- Academic Support |
- Documents |

- | Requirements |
- Compilers |
- Validation |
- RTOS |
- Analysis |
- Hardware |
- Software |
- Resources |
- Products |
Tracealyzer for Linux
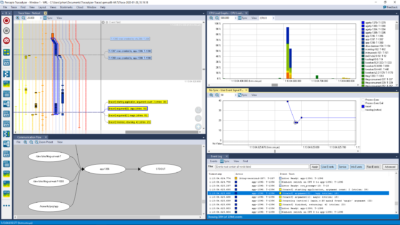
Tracealyzer for Linux gives an unprecedented level of insight into the run-time world of Linux-based software systems. This allows you to solve complex software problems in a fraction of the time otherwise needed, develop more robust designs to prevent future problems and find new ways to improve your software’s performance.
When developing embedded software based on an operating system, a traditional debugger is often insufficient to fully understand the software’s run-time behavior. A debugger shows the current system state and allows you to step through individual functions, but this is a low-level perspective that is not suitable for studying operating system behavior, such as scheduling, blocking and interactions between tasks.
Perhaps your code works fine in isolated tests, but errors occur when running the full integrated system? Your debugger can show you the system state once the problem has been detected, but how did the system reach this state? What tasks have executed, in what order, for how long, and how have they interacted? What input has been received, and when? How much of the CPU time is used by different tasks and interrupt handlers? Generally, what is actually going on in the run-time system?
Tracealyzer for Linux visualizes the run-time behavior of your embedded software through more than 20 high-level views that complement the debugger perspective with the “big picture”. You may have used some trace tool before, but this is something extra. The views are interconnected in innovative ways and are very simple and intuitive to use, which makes Tracealyzer a very powerful analysis tool.
Tracealyzer provides an unprecedented insight into the run-time world of your system, that gives several high-level benefits in your products development. Solve complex software problems in a fraction of the time otherwise needed, develop more robust designs to prevent future problems and find new ways to improve your software’s performance.
Tracealyzer for Linux uses the widely used LTTng tracing framework for recording the target system behavior and support both the LTTng v2.x and the older LTTng version used in Wind River Linux 5. Since this is a pure software solution, you don’t need an advanced hardware trace debugger to use Tracealyzer.
Tracealyzer can be used as a lab tool but also for post-mortem analysis. Some customers keep the recording active in their release build, which gives them very valuable trace diagnostics on real-world issues that otherwise would have been hard to analyze. LTTng can be configured as a “flight recorder”, that keeps the latest event history in a RAM ring-buffer, or to continuously store the trace to the device file system. You can control the LTTng recording directly from Tracealyzer via SSH.
Tracealyzer for Linux support both LTTng Kernel Tracer and User-Space Tracer (UST). LTTng UST allows you to insert tracepoints anywhere in your application and you can even instrument standard library calls without modifying the library source code. Tracealyzer for Linux allows you to configure how each tracepoint should be interpreted, as a service call or general user event, parameters, formatting, etc. This is further described in the User Manual.
Like all Tracealyzer products, Tracealyzer for Linux gives you a 30-day fully functional evaluation period and comes with a pre-recorded demo trace, that allows you to easily explore the features.
 |
Tasks, System Calls and User Events
|
 |
CPU Load
|
-1.png) |
Timing Variations
|
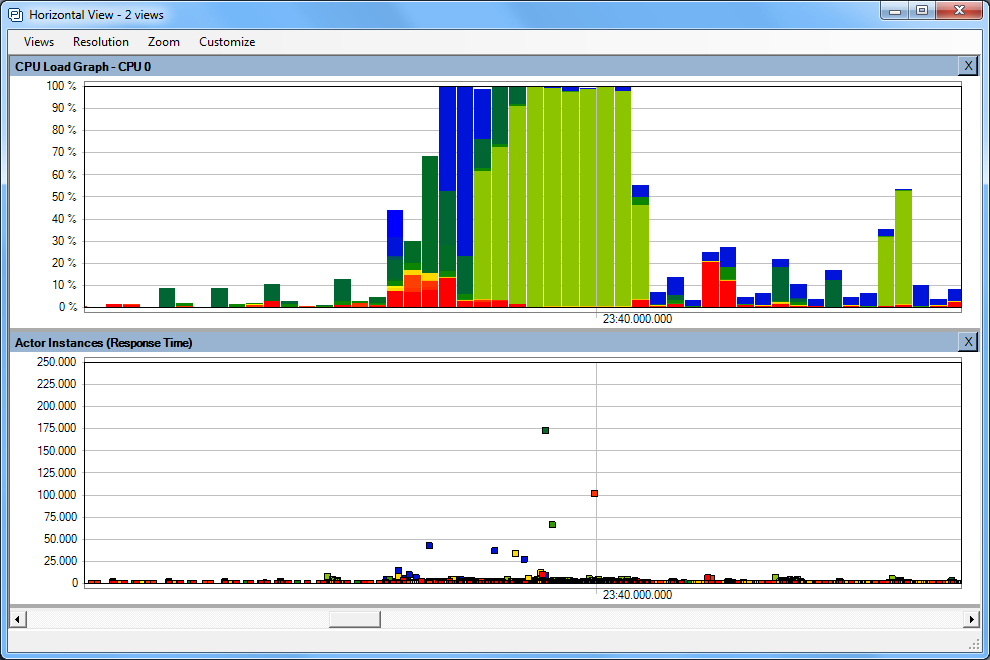 |
Show Multiple Views Synchronized
|
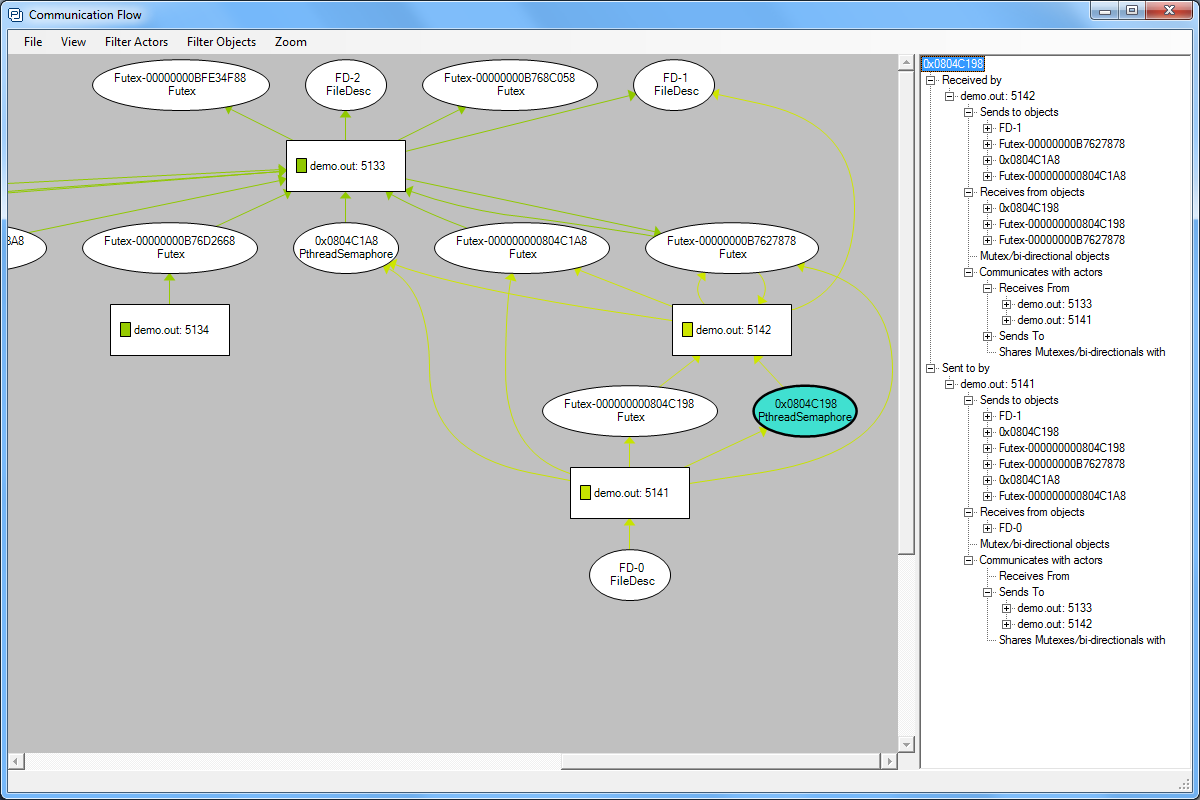 |
Communication Flow
|
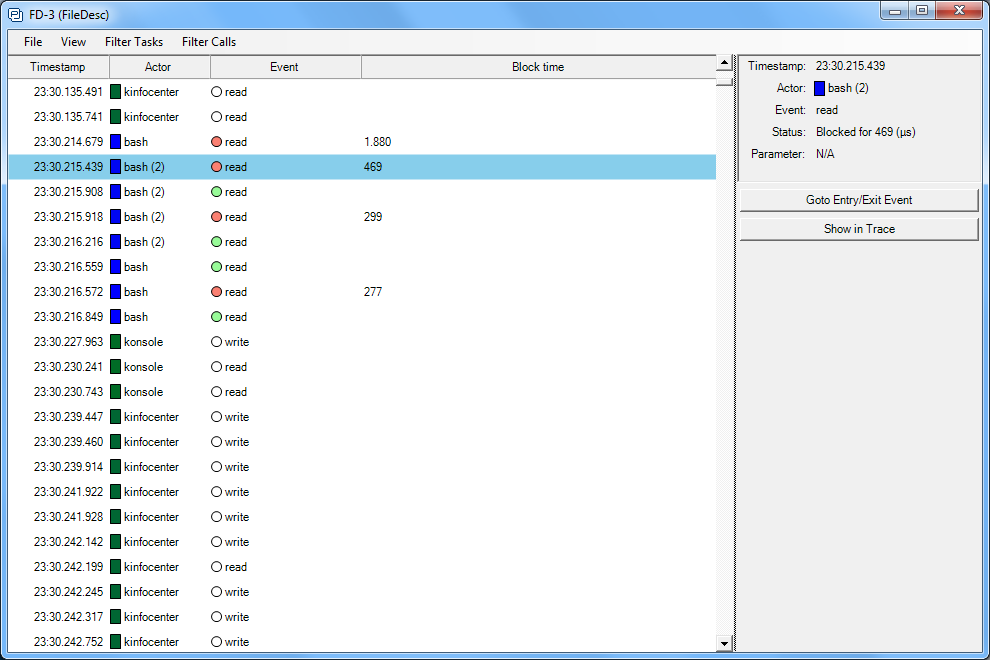 |
Kernel Object History
|
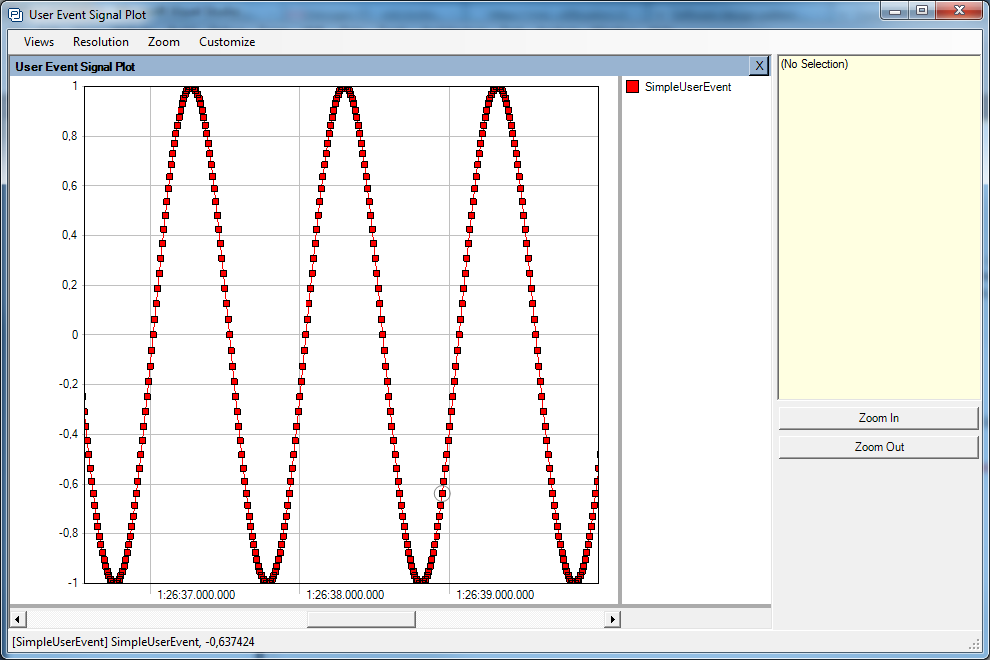 |
User Events and Signal Plots
|